Yeah, sorry was looking at the wrong project. This one is worse than cheating. You would need to compile one version of each algorithm depending on the blur-size, and then select the right one at runtime. But whatever works for you.
the Battle for the Fastest Blur continues…
Don’t the templated parameters mean that any implementation you use (blur size, contrast) will be baked-in at compile time?
Depends on your use case! I don’t know the structure @Toddler-Boy works within, but if portability and a sane maintainable api to work in a bunch of developers is your game, I have no argument with his criticism.
It’s inappropriate for an API, but in my case where I have strict control and nobody to answer to (except my future self, who, when this invariably no longer works with whatever pixel format I naively throw at it in 2024, will revisit this comment in shame), it works for now.
As for templating pixel type, you’d have to template the color channel count though and re-write some of the code to use it. It assumes RGBA in the specific layout that work with the pointer math in the method.
It would mean that
blurImage<10> (image);
blurImage<15> (image):
blurImage<20> (image);
would all get stampted out as separate functions. Not the worst thing in the world, but I doubt it’d be a significant performance gain - I’d be interested in seeing it run in a profiler against other approaches.
I looked at templating my approach, since dynamically allocating different amounts of memory based on the blur size was very inefficient.
In the end I settled on capping the blur size to 255 and just allocating the max memory needed. So it’s less efficient on memory usage, but much better for CPU which is the thing that needs addressing.
Doesn’t look like any of the other approaches make use of juce::ThreadPool which I found to have a huge impact, so I’d be interested in seeing if the other approaches have similar gains.
@Toddler-Boy the algorithm is run sequentially over all 4 channels. It works well with the default JUCE premultiplied ARGB image format.
@ImJimmi
Only values 1 and 2 make sense - anything above that would typically blur too much. This value is passed directly to the bit shift operation. The approach in the above algorithm is not based on a box blur but is essentially a 1st order IIR run forward and backwards. It also does not need a temporary buffer.
I never needed fine control over the blur amount, and the question always is, how many different blurs do you need in your code? But it might still be possible to replace the shift constant with a fixed point multiplication, which may not be bad for performance as long as the multiplication value is cached in a register or used as a constant, for example, by replacing the following code:
int px = int(p[0]) << 16;
s += (px - s) >> blurShift;
p[0] = s >> 16;
with:
int px = int(p[0]);
s = px*blurConstant + (s * otherBlurConstant >> 12);
p[0] = s >> 12;
blurConstant is 0 to 4095
otherBlurConstant = 4096 - blurConstant
(not verified, but should be similar to that)
One way how I can think this code can be improved is by dropping fixed point arithmetic and processing two channels at once with bit masking. Some vector rasteriser libraries do it this way. I.e., working with BBGGRRAA as BB00RR00 and 00GG00AA, masked via 0xFF00FF00 etc - these can handle additions and shifts with some restrictions and post-masking, which might be sufficient for a simple blur, but the blurImage(img) code worked well for me, so I didn’t bother with mental acrobatics to implement the latter approach.
Thanks,
George.
1 Like
This is fascinating George, thanks for sharing your knowledge!
Ahh I see, interesting! I hadn’t looked into how that worked in detail.
I’m inclined to agree - but our designers would not. We currently have this on our backlog because of how JUCE’s current shadow API is very slightly different to that in Figma:

So we’d need that super-fine control to get the shadows to look as close to tools like Figma, Illustrator, etc. as possible.
Shadows - maybe it’s best not to use any blur for it if possible, but draw them using linear gradients (and pixel-aligned radial gradients for the corners) or pre-rendered bitmaps (also based on gradients). What I needed the blur for is to get this effect:

JUCE has a convenient screenshot function for components, which can then be processed by blur and used as a background for the overlay widget. Obviously, this approach doesn’t support dynamic updates of the underlying widget, but in most cases, we could live with it.
/George.
1 Like
Two micro changes. Some compilers will complain about the if enhanceContrast statement or not eliminate the extra branch unless the code is more explicit:
if constexpr (enhanceContrast)
Second, clamps/jlimit are pessimistic, so the following can also help instead of jlimit in cases where the value will be in range the vast majority of the time such as mine. You have to profile to know with your compiler and options, but instead of jlimit or std::clamp, you can try:
template<T>
inline T limitOptimistic(T val, T min, T max){
if (__builtin_expect(val < min, 0))
return min;
if (__builtin_expect(val > max, 0))
return max;
return val;
}
I’ve been working with vdsp a bit and thought I may as well see what their Tent Blur looks like.
It looks very similar to stack (mainly looking at drop shadows in the moment)
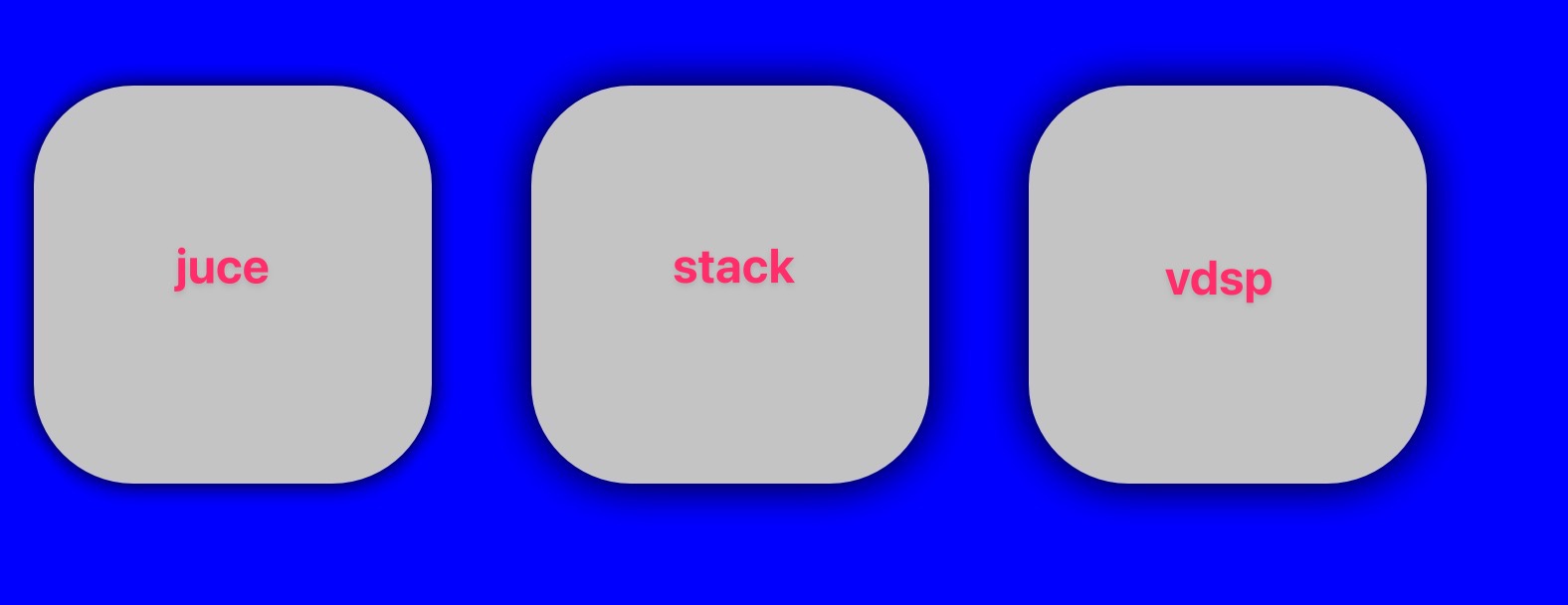
200x200px single channel blur on macOS M1 Release, vdsp’s Tent Blur is a bit faster than (FigBug)'s stack blur.
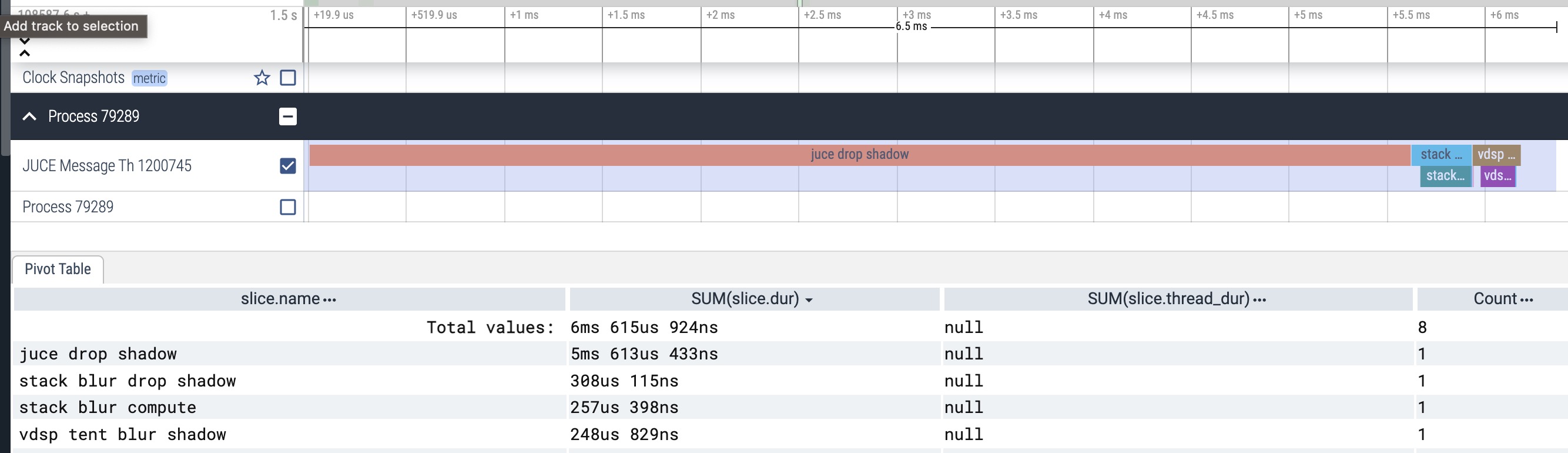
500x500px single channel blur on macOS M1 Release, vdsp seems to be > 2.0x as fast as Stack:

Edit: And seeing similar results on a 2015 Intel MBP
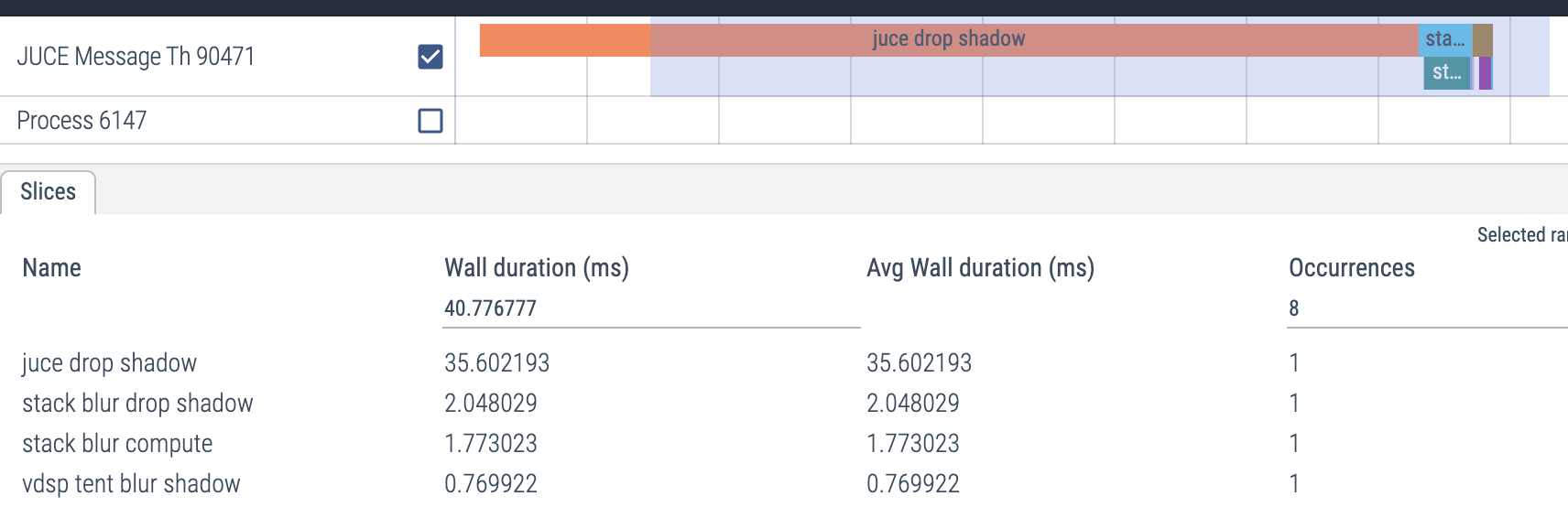
One nice thing about the vdsp route is it’s only a few lines of code:
juce::Image::BitmapData data(img, juce::Image::BitmapData::readWrite);
juce::Image::BitmapData blurData(blur, juce::Image::BitmapData::readWrite);
vImage_Buffer src = { data.getLinePointer(0), height, width, (size_t) data.lineStride};
vImage_Buffer dst = { blurData.getLinePointer(0), height, width, (size_t) blurData.lineStride};
vImageTentConvolve_Planar8(
&src,
&dst,
nullptr, 0, 0,
radius * 2 + 1, radius * 2 + 1,
0, kvImageEdgeExtend);
I’ll check out the similar functions for IPP on Windows… It makes sense to me to move all vector/matrix stuff where possible (both image/dsp) to these highly optimized libraries.
7 Likes
@sudara The ‘Tent’ blur sounds very promising, we would call that ‘low hanging fruit’ for the JUCE team!
Ok, I tried out Intel’s FilterGaussianBorder on 500x500px - they don’t seem to have a more efficient blur option and I was too lazy to write a custom kernel for tent convolution.
Overall, it’s slightly slower than Stack on my current machine (AMD Ryzen 9 5900HX), which is maybe to be expected since Guassian does a lot of work…

One note: drawImageAt seemed strangely expensive on Windows (I showed a milder version here), regularly taking up to 5-10ms to draw the 500x500px image, which seemed a bit suspicious? I saw this on the mac machines too, but it seemed to only do that on first paint or two, so I assumed some allocation or memory cache effect was happening. Notable, because in those cases the drawing of the image is 5-10x more expensive than the creation of it, taking the whole operation it out of the “safely animatable” range of timings (I consider this to be <5-10ms on nicer machines).

The ippi API is pretty gross, requiring in/out vars, many calls to prep things, manual custom allocation/freeing. Had no idea what to choose for the Gaussian sigma (or what’s normal), so I tuned it by eye:
// intel calls the area being operated on roi (region of interest)
IppiSize roiSize = {(int) width, (int) height};
int specSize = 0;
int tempBufferSize = 0;
Ipp8u borderValue = 0;
ippiFilterGaussianGetBufferSize(roiSize, radius * 2 + 1, ipp8u, 1, &specSize, &tempBufferSize);
auto pSpec = (IppFilterGaussianSpec *) ippsMalloc_8u(specSize);
auto pBuffer = ippsMalloc_8u(tempBufferSize);
ippiFilterGaussianInit(roiSize, (radius * 2 + 1), 10, ippBorderRepl, ipp8u, 1, pSpec, pBuffer);
auto status = ippGetStatusString(ippiFilterGaussianBorder_8u_C1R(
(Ipp8u *) data.getLinePointer(0), data.lineStride,
(Ipp8u *) blurData.getLinePointer(0), blurData.lineStride,
roiSize, borderValue, pSpec, pBuffer));
ippsFree(pSpec);
ippsFree(pBuffer);
Anyway, I went down this path originally because I thought it would be interesting to try a IPP/vdsp optimized version of stack blur, but got distracted by these built in functions. Pretty neat those are included. I might eventually try writing a stack blur algo, but it’s back to work for now!
2 Likes
[quote=“sudara, post:75, topic:43086”]
One note: drawImageAt seemed strangely expensive on Windows (I showed a milder version here), regularly taking up to 5-10ms to draw the 500x500px image, which seemed a bit suspicious?
[/quote]If the DPI scaling factor is not 1 drawImageAt will have to resample the image, so that might be at play here.
We recently discovered high CPU overhead while using fillAlphaChannel = true in juce::Graphics::drawImageAt, which was used in the first version of our Stack Shadow (there’s an old PR somewhere up there ^^^). This was only when using the JUCE software renderer, so we updated the algorithm to create a second juce::Image and fill the alpha channel of the shadow path in to that (much less CPU time), then draw that image straight in to the juce::Graphics context.
I’ll update the old PR with this update at some point because it made a significant performance improvement, but it went something like this:
void StackShadow::drawOuterShadowForPath (Graphics& g, const Path& path) const
{
...
{
...
applyStackBlur (renderedPath, blur);
juce::Image renderedPathTwo (juce::Image::ARGB, area.getWidth(), area.getHeight(), true);
{
juce::Graphics g2 (renderedPathTwo);
g2.setColour (colour);
g2.drawImageAt (renderedPath, 0, 0, true);
}
g.drawImageAt (renderedPathTwo, area.getX(), area.getY());
}
}
I haven’t kept up with the other implementations suggested here, but this may be helpful to someone! You could also split some of the functionality out to allow for the shadow images to be pre-generated and cached somewhere for faster use later. Maybe I’ll add that, too…
2 Likes
All good info, thanks!
I went on a Stack Blur deep dive tangent recently and a) figured out how it worked (which wasn’t easy for me, blog post coming soon) and b) implemented and benchmarked like… 12 versions of it so far? It’s been a fun side project to poke at when UI work is driving me crazy ![]()
I still need to look at a windows IPP implementation, but so far the fastest route I’ve found is going back to convolution via vDSP, which can see up to 16x improvements on larger images on my M1 (more conservative ~2x improvements over stack blur on smaller (UI-sized) single channel images, ie for drop shadows).
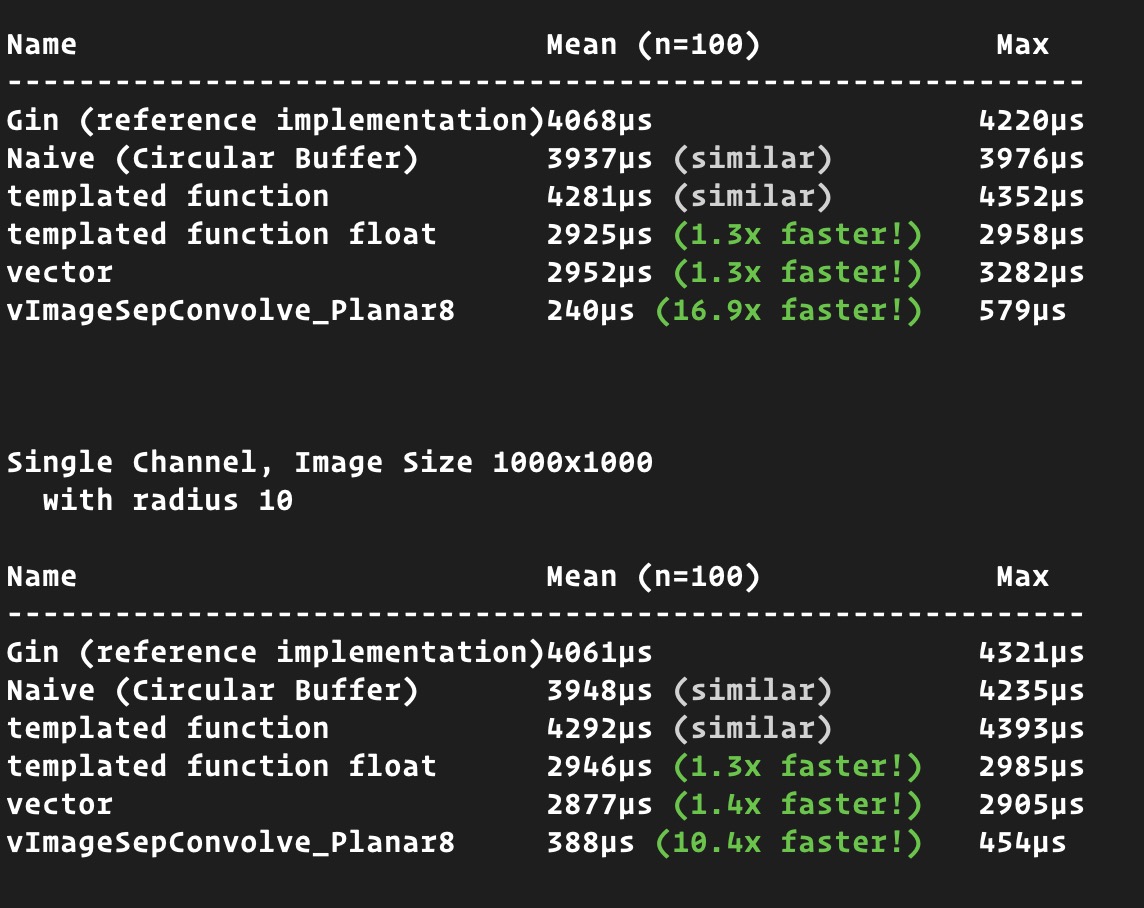
Stack Blur was written in 2004 and was really built for the pre-SIMD days. Since then both intel/apple have heavily invested into making convolution quite fast on CPU (vector processors, SIMD, etc). Even though I worked hard on learning the algo, it does make sense to me that backing up a step and letting the vendor CPU libraries do their thing ends up fastest. Especially for small radii (like under 20-30).
4 Likes
Coming back to this… as far as you understand it, is the problem that fillAlphaChannelWithCurrentBrush needs to be true for the single color image to paint “as is” (without it multiplying against the alpha in the existing graphics context?). It does look like there’s a lot of extra work when it’s true, including creating a new temporary image.
I wonder if in an ideal world the blurring would shortcut this step and return a RGBA image, maybe via Image’s convertedToFormat function. I’ll investigate…
This is what I’m doing and it makes a ton of difference. I’m working on a module to open source which only updates the shadows when a path changes (using the fast intel/apple convolution route).
1 Like
Just did a round of benchmarking on macOS/M1. Caching the shadows is definitely the most impactful change:
- For a 20x20px path with two shadows (36/48px) the time drops from 454µs to 4µs for cache hits.
- For a 50x50px path with the same two shadows, the time drops from 398µs to 14µs for cache hits.
- For a 500x500px path with same shadows, time drops from 2550µs to 294µs for cache hits.
These cache hits times include @LukeM1’s optimization which I confirmed bring a 2-3x speedup to the cache hit time (depending on image size). That’s accomplished by using another temporary graphics context/image to drawImageAt the single color to ARGB with fillAlphaChannelWithCurrentBrush set to true (which lets us avoid setting fillAlphaChannelWithCurrentBrush to true when drawing onto the main graphics context).
So those were the two remaining improvements I could find (on top of the move to a vectorized stack blur)
Other things I looked into:
- Using JUCE’s
convertedToFormatto convert the single color to ARGB (it didn’t pass the tests, didn’t look deeper) - Reducing the clip region before drawing to the main context (but drawImageAt already of course already does this under the hood)
- Replacing the single channel
drawImageAtwith vImage calls that manually construct an ARGB image from a single channel (Core Graphics already all the same fancy vector stuff under the hood, so it was all pretty quick, no time saved). - Using
excludeClipRegionto avoid drawing shadow pixels in places that the the filled path will then overlay:

That seemed to provide a small speedup to the cache hits when the fill path is large enough to make a difference (~15% when exclude region is 500x500), but I’m not sure the added complexity is worth it.
I also profiled the benchmark at this point and found the majority of remaining time is spent only in the main context’s drawImage call. Mission accomplished?

I’ll provide some more benchmarking numbers on the end result repo I’m chewing on…
5 Likes
Let me find some time to push up the changes I was talking about somewhere (I’ll make a separate repository with just the shadow code in, rather than muddying the waters by forking JUCE and pull requesting), but it sounds like we’ve both come to the same conclusion, which is encouraging!
The optimisation I mentioned above basically was the difference between Voca (shameless plug: Sonnox Voca | The Fast-track to Flawless Vocals | Sonnox) GUI being usable and not. And we didn’t even have to bother with caching the shadow images as the overhead for all of the smaller shadows (inner shadows on the rotaries, drop shadow on central drag handles, etc.) was acceptably small.
1 Like