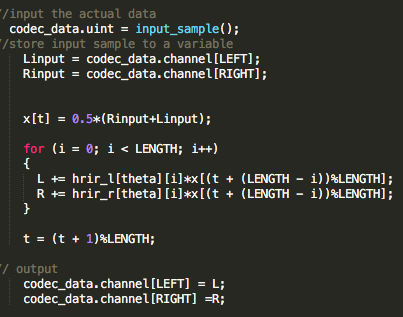
I think you are having several separate problems here. First one: Understanding of what happens in processBlock
So, why did you use const auto Length = buffer.getNumSamples(); and not const int Length = 512; if you are sure that it will always return 512 and your code relies on that assumption? The answer is, that buffer.getNumSamples() obviously can return any number of samples. And your code should be designed in such a way, that it can handle any number of samples. Don’t expect anything, just be prepared for every value. Now if your HRIRs have a length of 512 samples and you expect that buffer.getNumSamples() returns 512 in every situation, your code is likely to break in the first moment when it returns a value greater than 512 and will produce an unwanted result if it is smaller. So iterating over Length in the inner loop doesn’t make any sense, while the outer loop is fine, as it just handles the number of samples passed to it.
Second: Understanding how to do real-time convolution.
If you convolve an input signal with the length of 10 samples with a impulse response of the length 512, the resulting output will be 10 + 512 - 1 = 521 samples long. Now think of a signal with the length of 20 samples, convolved with the same impulse response. This will result in 20 + 512 - 1 = 531 output samples. Now what block-based audio processing is doing is to split data up into blocks. Just think you want to compute your 20 input samples in two blocks of 10 samples but still want to expect the correct number of output samples. Therefore you will need to compute all 521 output samples of the first block, write the first 10 into your output buffer and store the remaining 511 samples you generated for later use. Now compute the second block and add the remaining 511 samples from the previous block to the first 511 samples of the new 521 samples result. Then go on and return another 10 samples and store the rest for later use. Now you returned two times 10 samples and still have 511 in memory, which is 10 + 10 + 511 = 531 and therefore matches the theoretical result for a 20 sample input signal. Of course this can be done with a variable-sized input buffer. If it gives you 500 samples in the next call, just return 500 samples and store 21 for the next block and so on… But not storing any data will result in anything but not the expected convolution-result.
Third: Proper way of loading a HRIR.
Embedding the HRIR arrays in a static header file is a well-working way for doing a quick test. However in a real-world application you would probably like to load a variable-sized HRIR from a .wav file, read this file(s) at startup and then work with the content as you just did. This makes your application flexible enough to work with any HRIR.
Fourth: Length of your HRIRs.
Where do you get your HRIRs from? Did you measure them by yourself or did you use HRIRs from an existing database? Because normally you should chose the length of your HRIR based on the original data’s length and not just choose to use 512 samples just because processBlock seems to always use that number of samples. That said, I know of significantly longer AND shorter HRIRs, depending on the measurement setup. So before artificially making your original data longer by zero-padding (–> waste of resources) or even worse just cutting the end of your original data, you should just stick to the number of samples supplied by your database.
Fifth: Time-Domain-Convolution.
Doing such a convolution in the time-domain is possible but in most real-world-applications you would rather compute it in the frequency domain and therefore use HRTFs instead of HRIRs. I would advise you to take a look at that topic. And even if you want to stick to Time-Domain-Convolution you should have a read on efficient ways to implement them with ring-buffers and other tricks. Or just stick to the JUCE-classes such as dsp::FIR (Time-Domain) or dsp::Convolution (Frequency-Domain).
If you need any deeper information on that topic, I did my bachelor thesis on real-time binaural synthesis. This publication helped me a lot to get started: Partitioned convolution algorithms for real-time auralization. And if you by chance understand german, just drop me a DM and I can send you some extracts of my bachelor thesis.