I am working on building a compressor plugin from the ground up as an exercise and was debugging an issue in my level detection when i noticed that simply converting the data in the main audio buffer to decibels and then converting back creates a strange distorted sound in the signal without any additional processing. I have a convertBlockDataToDecibels function:
void Compressor::convertBlockDataToDecibels (AudioBlock<float>& block)
{
for (auto i = 0; i < block.getNumChannels(); ++i)
{
auto* data = block.getChannelPointer(i);
for (auto j = 0; j < block.getNumSamples(); ++j)
data[j] = Decibels::gainToDecibels(data[j]);
}
}
and a convertBlockDataFromDecibels function:
void Compressor::convertBlockDataFromDecibels (AudioBlock<float>& block)
{
for (auto i = 0; i < block.getNumChannels(); ++i)
{
auto* data = block.getChannelPointer(i);
for (auto j = 0; j < block.getNumSamples(); ++j)
data[j] = Decibels::decibelsToGain(data[j]);
}
}
and when I limit the processing to just these two functions back to back I get issues with the sound. I’m wondering if there’s something wrong with this approach, maybe each sample can’t be converted that way for some reason?
You can’t go to log space from the original signal. At the very least you need to square it or take abs, possibly do some short smoothing before going to db. You can’t take log of a negative number, and it’s usually not good to log without some smoothing, as your squared or abs signal will go to zero regularly, and db(0) = -inf, which will be clipped to some fixed value (-100 by default in juce::Decibels).
the signal that you are generating for this dsp processor should be an envelope follower from your input signal, but without modifying it. only once it is that you can make a gain reduction signal and only then use that on the original signal
It’s exactly like that, decibels are not meant to represent sample values. A stream of samples is a series of numerical values that approximate the shape of the actual sound wave. In our environments, these values are usually in the normalised -1.0 to 1.0 range.
The perceived level of an audio signal like that is determined by
the absolute max value of positive and negative peaks in the waveform – called the peak level
the integral of the area under the waveform which is somewhat approximated by the RMS value
If we want to change the level of a signal, all of its sample values are multiplied by a certain factor to scale the wave form.
Now if levels are measured or gain is applied and we do that using the numerical domain of normalised 0 to 1 values we quickly notice that these factors do not necessarily match with the perceived change in loudness. This is where dB comes into play as it maps the loudness changes expressed by linear factors onto a logarithmic scale that approximates the perceived change in loudness a lot better. But, as both level measurements and linear gain factors are always positive numbers, the dB conversions are designed to convert positive linear gain values into the db domain and the other way round.
Now if you put a sample stream consisting of positive and negative values into a db conversion function, all the negative values will result into complete nonsense values. Converting the sample stream back will not restore the negative half of your signal. This is why you are perceiving a distorted signal after your operation.
So long story short: Always treat your actual samples as linear values and use dB for computing level measurement and gain. To apply a gain of some dB to your signal convert that dB value to a linear gain and multiply it with your samples.
To put my answer in the wider context that PluginPenguin described: dB is just one way to go from a linear to a log scale, which makes sense for things that are perceived in a roughly logarithmic way, like level/loudness. (Pitch is another one: in that case you’d use something like log2(frequency), which gives you octaves. Pitch in octaves is to frequency what level in dB is to amplitude.) Now, to go from amplitude to level you need to have amplitude first, and the amplitude of a signal is not just the signal itself. You don’t perceive “negative amplitude”: a negative peak is just as loud as a positive one. So you need to extract the positive amplitude of the signal, its amplitude envelope: you need an envelope detector/follower. There are roughly two ways of doing that. One takes the absolute value of the signal (aka full wave rectification), then applies some kind of smoothing (lowpassing). The other one squares the signal, then applies some smoothing, then takes square root. The smoother can be just a lowpass (a roughly symmetric smoother, which takes as much time to rise as it takes to fall), or it can be biased to rise and fall at different speeds, with attack/release controls. The sequence squaring-symmetric smoothing-square rooting is known as RMS, the Root of the Mean of the Squares. Usually, a detector that takes abs and applies asymmetric smoothing with short/zero attack is called a peak detector.
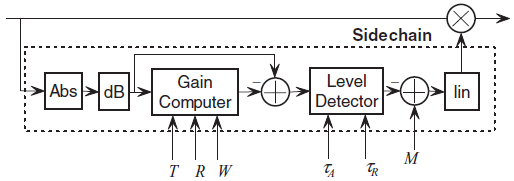
You’ll see some compressor diagrams that take abs, then go straight to dB and gain computation. For example:
This may be ok theoretically, and you do need a smoother after gain computation, but it’s usually good to have another, short time smoother between abs and dB. The abs or squared signal falls to zero, or -inf dB, on every zero crossing of the input, so you’d be tasking the process with a constantly huge range, and worse, your dB may be clipped to a not very low value, introducing a lot of discontinuities. It’s better to take dB on something that actually represents the signal’s envelope.