I hope it’s OK to ask generic C++ stuff here…
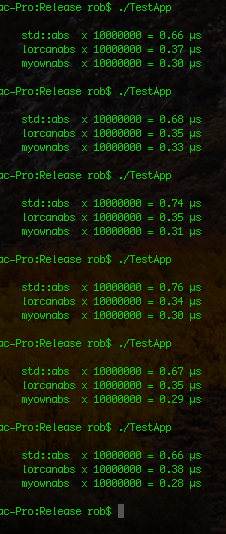
I’m playing around with various optimizations and approximizations, just having fun and trying to squeeze the odd microsecond out here and there. So I wrote my own approach to a function that turns a value into its absolute (positive) value, basically to measure it against std::abs(). This is my implementation:
namespace Math {
template <typename TYPE>
inline const TYPE Abs (const TYPE& Value)
{
return Value + (Value < static_cast<TYPE>(0)) * static_cast<TYPE>(-1);
}
}
I have measured and timed it, my own abs() is slower in a debug build, but usually more than 2x faster in a release build, so I really want to keep it in my framework.
![]()
In this simple little wavefolder snippet, I tried to use my own Math::Abs instead of std::abs, obviously to get the performance benefit:
const double sign = Math::Sign(Sample);
double value = Math::Abs(Sample); // <--------------------- this call works fine
while ((value > 1.0) or (value < 0.0))
{
const double positive = Math::Abs(value); // <--------- this call halts the host
value = (value > 1.0) * (1.0 - (value - 1.0)) + (value < 0.0) * positive;
}
So when I use my Math::Abs to get the absolute value of the current sample at the beginning, it works just fine and does what it’s supposed to. But as soon as I use it inside the while loop, the host just halts and stops responding when the project loads.
If I replace the Math::Abs call inside the while loop with a call to std::abs, everything works fine again, host loads project, sound is there. Swap std::abs for Math::Abs again, host stops responding on project load and I have to kill it.
I tried playing around with everything about the Math::Abs implementation, making it non inline, non const, making the argument non const, non reference, even using a dedicated variable before the return. I even put the result of the Math::Abs call into a variable inside the while loop, to make sure there’s no trouble with assigning and referencing the same variable in one line.
But nothing helps, it just keeps halting the host.
Anyone got a clue why that would be the case?



 (except for closing that missing bracket):
(except for closing that missing bracket):