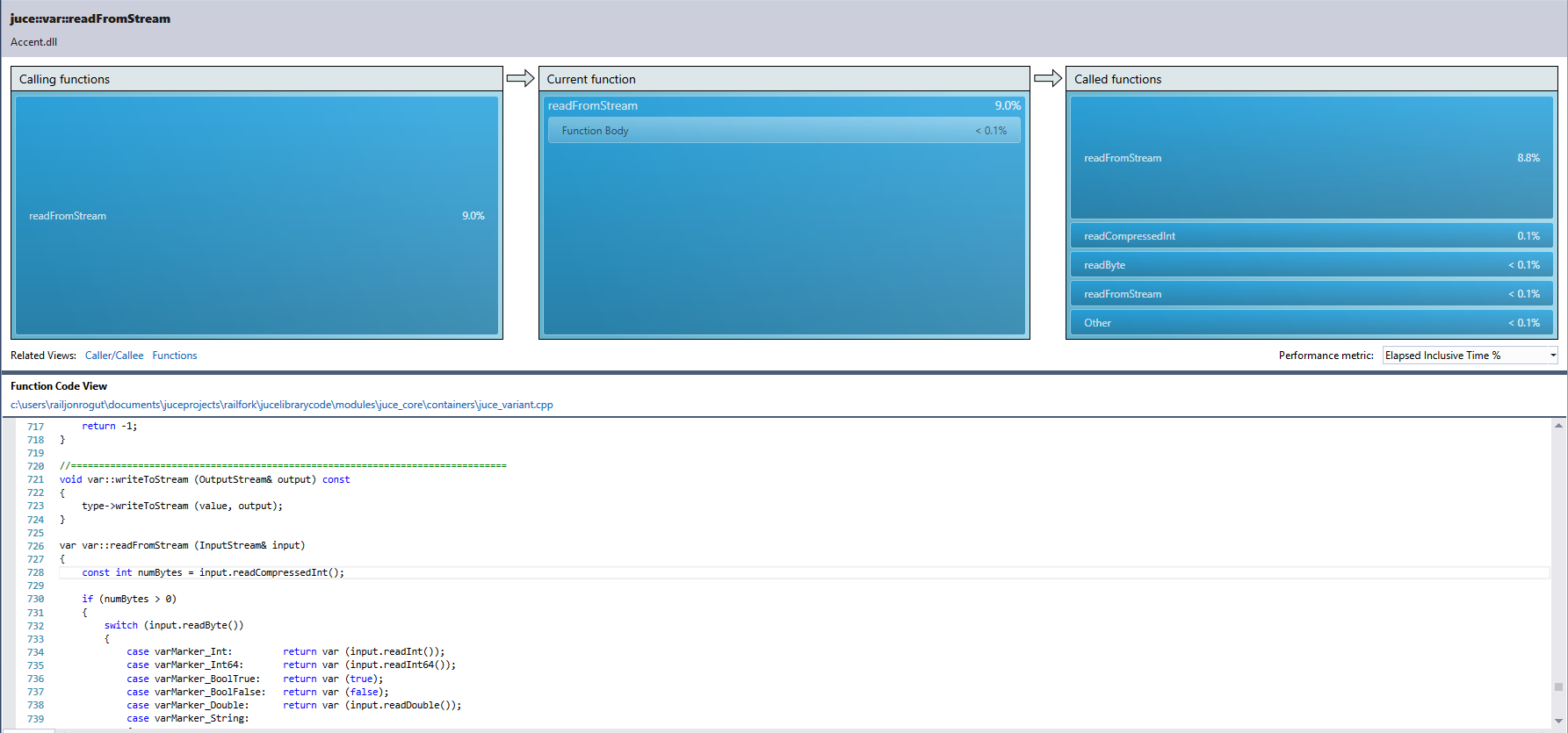
Anyone figured out a way to improve the speed of ValueTree::readFromStream() on Windows? On Mac reading the exact same data stream takes 2 second, on Windows it takes 8 seconds on an SSD and as long as 45 seconds on a Parallels Mac drive, between 20 to 30 seconds on the VM.
I have excluded all relevant files in Windows defender… and I see that openHandle already uses the FILE_FLAG_SEQUENTIAL_SCAN flag.
I have a Plan B to move this piece of code into my Installer, but figured I’d ask.
Hmm, it’s difficult to tell with only a partial profile like that. Does your tree have a lot of arrays in it?
At a guess I would say that it’s just taking a long time to read from the stream but you’d need to dig a bit deeper in the profile to prove that.
How big are the ValueTrees on disk? Is there lots of stream repositioning going on? Would it be possible to memory map or simply load the whole file into memory first and then read it?
The Tree is pretty simple and has no children - the main issue is that the performance reading the exact same file (which is way too large to put into memory) is different when running the code on MacOS vs. Windows – it has to be a disk speed issue when reading small amount of data sequentially… but the performance difference between the two platforms is dramatic.
Did you try putting a BufferedInputStream in front of the stream that reads from disk? If you do that with a large buffer then the disk accesses should be pretty much optimal.