The files are not compiled for DirectX, how do you come to this conclusion?
The picture you referenced just shows that you can use SPIRV-Cross to “cross compile” the SPV representation back to GLSL, HLSL … and then use it for your desired API (GL, DirectX, Metal). This is another usecase of SPIR-V and doesn’t matter here.
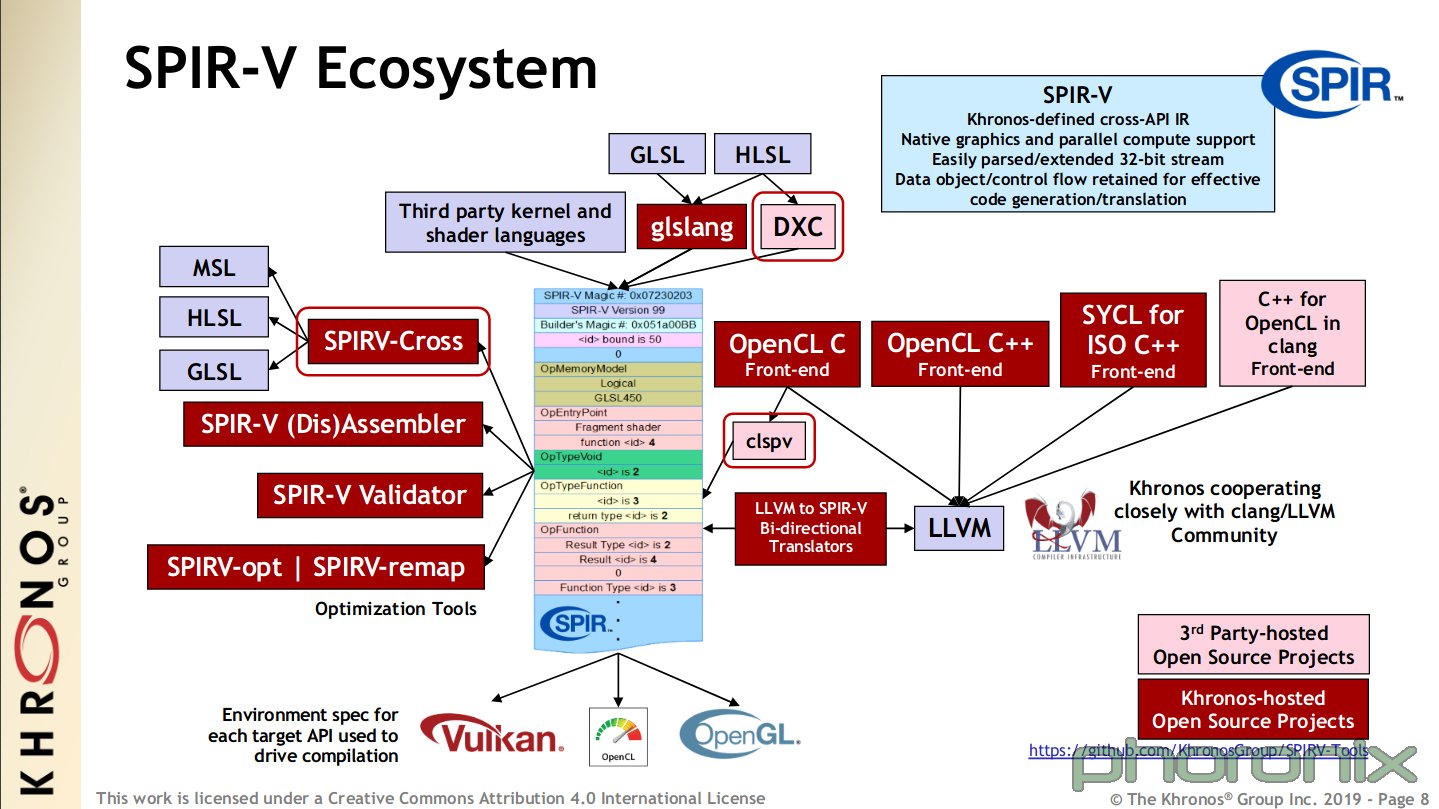
If you take a look at the SPIR-V Ecosystem diagram:
Starting at the top middle. The shaders in the repository (.frag and .vert) are in GLSL!
They are compiled into .SPV using glslang, the GLSL Language Compiler (bin/glslc.exe in the Windows Vulkan SDK).
When constructing the graphics pipeline and creating the shader modules, the SPV code is directly loaded as uint32. Reading Standard Portable Intermediate Representation - Wikipedia
and other references, it seems like the intention of SPIR-V is to be direcly used by the API. Portable!
Also take a look here: MoltenVK | User Guide | About
[…] Metal uses a different shading language, the Metal Shading Language (MSL), than Vulkan, which uses SPIR-V. MoltenVK automatically converts your SPIR-V shaders to their MSL equivalents.
So am I overlooking something or what’s all this about?
Again: Have you mistaken the ImageType implementations as the context one? There are actually two methods to initialize Graphics.
- One from a wrapped VulkanImage (VulkanImageType), which doesn’t use an OS surface.
- Another using the VulkanContext and a swapchain image (framebuffer).
Because what you describe isn’t really happening.
-
For each new frame (when an OS repaint happens) a swapchain image is acquired (not allocated). The allocation of this image depends on the window size and is managed by the OS.
-
The graphics context (when the window is visible) creates and caches a VulkanImage (used as framebuffer on device local GPU Memory).
-
The graphics class renders into this framebuffer. But only for invalidated regions.
-
The whole framebuffer is rendered to the OS swapchain image/framebuffer using one fullscreen quad.
Aside from offscreen rendering, this is the standard method to directly render to an OS surface. Where is the high memory consumption and unnecessary CPU overhead?
I don’t think this is true. The Vulkan SDK on Mac is offering the regular headers and so on, true. But to actually implement the API, MoltenVK is used under the hood to translate the calls to the Metal equivalents →
MoltenVK
This SDK provides partial Vulkan support through the use of the MoltenVK library which is a “translation” or “porting” library that maps most of the Vulkan functionality to the underlying graphics support (via Metal) on macOS, iOS, and tvOS platforms.
Could it be that we talk about different things here? I’m a bit confused about what you mean with primitives and your assessment of what actually happens in the pw_vulkan and pw_vulkan_graphics module.