Hey everyone, hope you’re all doing well!
I’m currently trying to work out the best practices when it comes to using the te::TransportControl::ReallocationInhibitor. \
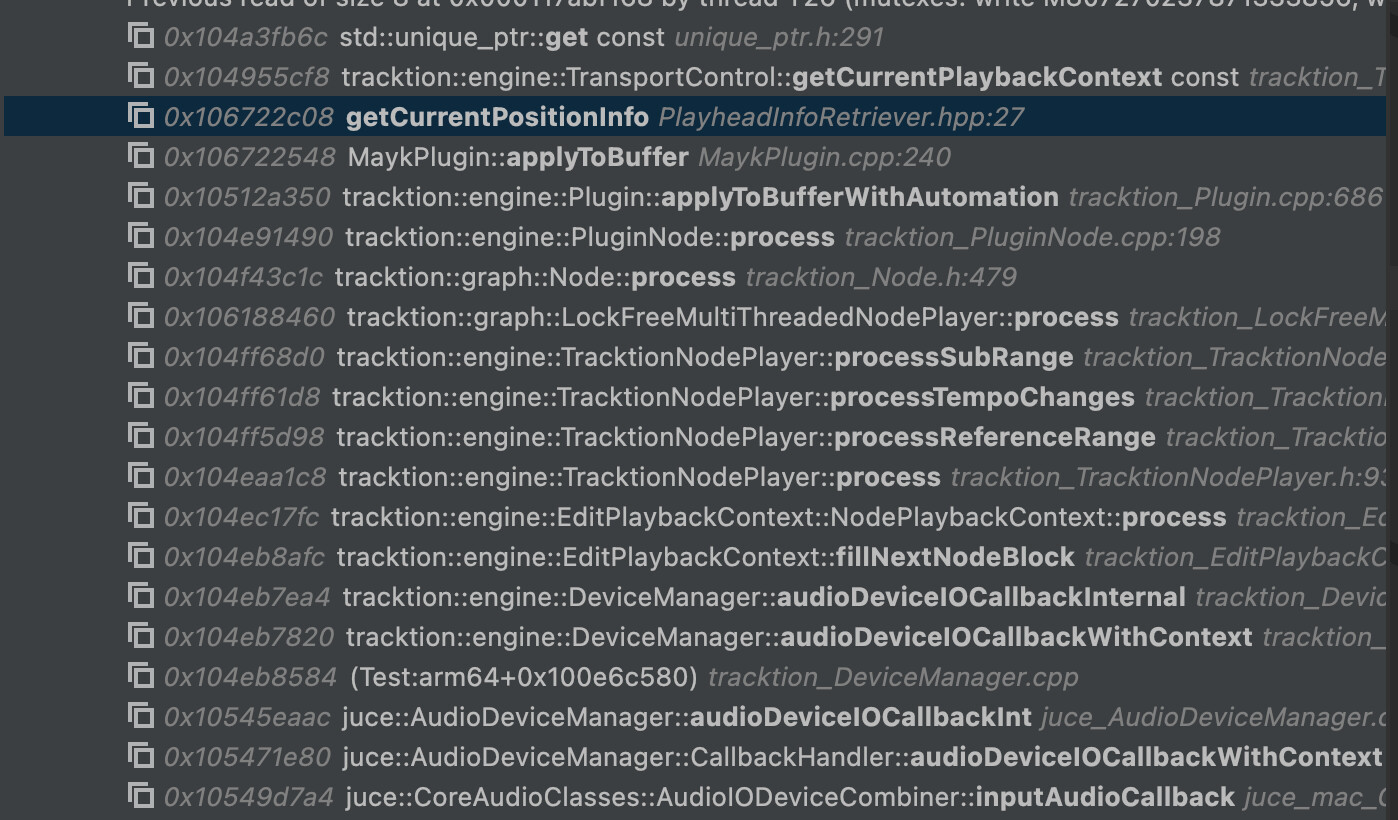
I’m currently trying to tackle crashes which are occuring on the audio thread when the message thread is tearing down the plugin graph during playback. The crash will typically occur in some kind of Node::process type function, and the message thread will have just destoyed the Node that was playing.
The most common place this happens is when calling AudioClip::rescale, during playback, but can also happen when adjusting the master bus volume.
I’m currently using these functions in our engine play() and stop() respectively:
/**
* This function should be called whenever we want to declare that the audio engine is currently playing, and we want
* to prevent tearing down and rebuilding the audio graph. This will prevent the `Node::process` flavour crashes.
*/
void disableTransportAllocation() {
if (!reallocationInhibitor) {
reallocationInhibitor = std::make_unique<te::TransportControl::ReallocationInhibitor>(edit->getTransport());
}
}
/**
* This function should be called whenever the engine is stopping playback, and it is now safe to rebuild the plugin
* graph.
*/
void enableTransportAllocation() {
// delete the reallocation inhibitor
reallocationInhibitor.reset();
}
std::unique_ptr<te::TransportControl::ReallocationInhibitor> reallocationInhibitor;
TLDR; how do you use te::TransportControl::ReallocationInhibitor ?