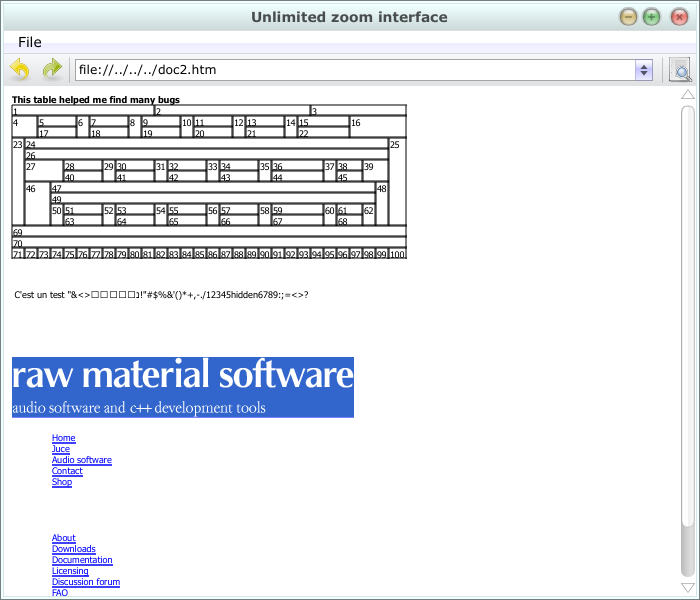
Here it is. Coming from the dark side of the Internet, I introduce you an HTML4.01 compliant parser and renderer.
The parser and mapper uses some fundation classes for a bigger project I’m working on. However, the renderer uses Juce, and there is a Juce based BrowserComponent.
I’ll try to keep this thread as updated as possible about the current development state, and bug.
A link on the project can be found :UZI project
The lastest Win32 compiled version is here
Ok, let’s speak about the functionnalities:
[list]
[] Implemented HTML 4.01 compliant parser[/]
[] Implemented DOM2 interfaces and tree[/]
[] Implemented CSS2.0 box rendering algorithm[/]
[] Implemented a stupid HTTP client[/]
[] Implemented a Cache engine[/][/list]
and what is (still) missing:
[list]
[] HTML element’s attribute are currently ignored in the rendering (need to map them to CSS properties) [/]
[] CSS properties parser is not finished (disabled)[/]
[] CSS rule selection is not done at all (current CSS rules are default CSS stylesheet as defined in the standard)[/]
[] Browser doesn’t allow clicking on hyperlinks (ok, it will be done very soon)[/]
[] HTTP Client need supporting POST request, and the content-refresh properties[/][/list]
There are still lots of bug, from stupid rendering bugs (I’m investigating), to hideous one.
[size=92][For example, when you type in an address, and the webpage contains recursive table, the rendering process stop prematurely. You can force it to restart by resizing the window.]
[By default, it’s HTML transitional DTD that is selected, even if the document state differently.]
[/size]
Please report any bug with URL so I can check it out.
If it’s a dynamic website, you can save the current document in the file menu.
You also have 2 error consoles, one with the HTML content, the other with HTML errors found in the current document.
If you are interested in helping me, I’d give you an account in assembla so you can commit to the repository too.
I’m sure, that it would be much better to have an HTML engine for JUCE instead of a full functional browser. It’d let people to use html files in an interface design. Maybe I’ve missed something and you’re goning to do that, right?
Well, it’s not a fully functionnal browser (as, for example, hyperlink are not followed, nor clickable).
Initially it was supposed to be an fully compliant HTML renderer (a code to render HTML not browse the web).
I still have work to do on it, but it currently allow to display an HTML source (whether it is local or on the internet).
The next step will be bug correction (table inside table cause a missing recursion rendering problem), and attribute mapping to CSS properties (I’ve started doing so for table through).
It’s important to understand that some part of a browser must be implemented to display any HTML content. HTML is just a structure and text based content. As soon as you want some style informations (text color, font, …) or images, you need a fetcher to get those (externally on the web, or memory based content, or local files, too) linked content.
If you are interested in having a look, please read the documentation.
Well, I’ve updated the repository with a new version.
This version improves HTML parsing (now documents are checked against Traditional DTD, and error are corrected on-the-fly, if possible).
The browser now have browsing facilities (you can now click to follow an hyperlink)
There is a DOM Tree viewer component, so you can compare with that of, let’s say, Firefox on document error
There is an error component (so you can understand why the document you want to display doesn’t display properly…)
And you can save a document you’ve fetched as-is, so it’s possible to understand the error by looking at the source directly.
That’s for the good news.
There is still a bug in the table rendering algorithm, specifically recursive table rendering, left offset of boxes are zeroed, while they shouldn’t (it’s still possible to get them right by resizing the window) .
I’ll try to sort this out ASAP.
There is no POST nor PUT method yet, so you can’t query Google (will be done soon too).